AWS announced Aurora Limitless back at Re:Invent 2023, which “scales your relational database workloads on Aurora beyond the limits of a single Aurora writer instance without needing to create custom application logic or manage multiple databases” [3] – but before we get into how AWS achieved this, what does scaling “beyond the limits of a single instance” actually mean?
Scaling in Aurora Serverless
To understand the scaling capability of Aurora Limitless, we must first understand how AWS achieved the “regular” scaling of Amazon Aurora Serverless.
To frame the problem, imagine how we would implement database (write instances) scaling up and down. Traditionally, we would need to create an additional instance with adjusted resources and perform a failover. However, a more seamless solution would be to run the database on a large physical server and let it grow as needed – i.e. if it needs more resources, simply ask the underlying OS for more.
Now to not waste resources, we would run multiple database instances on the physical server. For AWS, the only adequate way to share resources while isolating workloads would be to use a hypervisor – in this case, we could use the Nitro supervisor, which is what Amazon EC2 uses to manage instances.
When an instance is launched using Nitro, it will reserve the amount of memory that was statistically requested at launch. This is how Nitro provides consistent performance for EC2 instances – which would normally also be great for databases, as database loves consistency! However, for serverless databases, this may pose a problem.
If a database wishes to scale up and requests more memory, the OS would not be able to allocate this as the memory allotment has been configured statically at launch – Nitro simply does not allow this. We would need to reboot the database with increased memory, which would be too inefficient for a serverless database.
To solve this, AWS introduced Caspian – a “cooperative oversubscription” system, where Caspian itself spans multiple innovations beyond just a new hypervisor. A Caspian instance, in contrast to a Nitro instance, is always set up to support the maximum amount of memory available on the host machine.
For example, for a database instance that requires 6GB of memory hosted on a 256GB machine: a Nitro instance would believe it has 6GB memory available, while a Caspian instance would believe it has 256 GB available.
But if the full memory of the underlying machine is available to the instance, how does it handle multiple instances on a single machine? In this case, the physical memory is allocated based on the actual needs of the database through Caspian’s heat management system – so when a database wishes to grow, it asks the heat management system for additional resources.
Continuing from the previous example: if we host two Caspian instances in the 256GB same machine: one that require 6 GB and another of 100 GB – the 100 GB Caspian instance will believe it has 156 GB of memory remaining, despite only 150 GB being left available on the machine. Analogously, the 6 GB Caspian instance will believe it has 250 GB remaining (despite only 150 GB left on the underlying machine). Both instances are “oversubscribed” to the underlying resource, cooperatively working together through the heat management system.
Additionally, if an instance wishes to grow but the underlying machine lacks sufficient resources to do so, an instance (which may or may not be the instance requesting more resources) will be moved to another physical host with sufficient capacity, to make room. Thankfully, this migration can be performed extremely quickly due to the high bandwidth and low-jitter networking provided by EC2 – so there is almost no performance impact on the database during such migration.
Note that Caspian does not just migrate when the resource is required – migrations are performed constantly based on predictions of which databases are going to require more memory, using Caspian’s heat management system. As it’s best to have resources available before we need them, this optimizes the performance of the Caspian instances fleet. This is how Amazon Aurora Serverless scaling works behind the scenes.
However, we are still not fully “serverless” – what happens if a database requires more than the physical limit of a single physical machine?
The Sharding Problem
To combat the problem of a database requiring more resources than that of the largest physical machine available (beyond just performing vertical scaling on the underlying machine, as this simply is not sustainable long-term), AWS introduced Amazon Aurora Limitless database. Amazon Aurora Limitless solved this problem through sharding.
Quoting from AWS, database sharding is: “the process of storing a large database across multiple machines […] by splitting data into smaller chunks, called shards, and storing them across several database servers.” [4]. Put simply, we overcome the limits of a single physical machine by partitioning data across multiple physical machines.
To shard effectively, data needed for frequent access should reside on a single shard for the shard to be able to execute more transactions locally (as a monolithic database would!). As such, with smart schema design, sharding could offer resources beyond the limits of a single physical server, with at least the performance of a monolithic one. This also allows seamless scaling of not just reader instances, but also writer instances.
However, sharding also introduces new problems and complexities, surrounding:
- Querying: Managing complex queries (such as JOIN queries) that span across different shards
- Scaling: Maintaining tasks such as scaling, backup, debugging and maintaining versions
- Consistency & Isolation: Some level of both is required for concurrent transactions to work as expected
Through clever design, Amazon Aurora Limitless is able to overcome each of these, guaranteeing:
- Single Interface: Uses distributed sharding architecture behind the scenes, but users can essentially use it as if it is a single instance database
- Transactionally Consistent across the entire system
- Able to scale up to “millions of write transactions per second and manage petabytes of data” [3]
- Features of Amazon Aurora – such as HA and Multiple-AZ deployments
Querying in Aurora Limitless
When using Aurora Limitless, 2 new types of tables are introduced:
- Sharded Table, and
- Reference Table
A sharded table, as the name suggests, is a table that is partitioned across the shards, where a shard key column of choice is hashed and used to determine which shard the data will be stored in. A sharded table can also optionally be collocated with another sharded table, which means that both tables share the same shard keys. This can be useful if specific partitions are frequently joined together.
A reference table is then a table that is stored in full, across every shard – i.e. it is not partitioned. This can be useful for small tables with low writes or if it is frequently joined across all partitions of another table.
Furthermore, given an Aurora cluster, Aurora Limitless will introduce a new “shard group” component which introduces a new endpoint for applications while handling both read and write requests. As the shard group is contained inside the cluster, any cluster-level operations such as backups or upgrades are also automatically applied to the sharded instances – there is no need to individually manage the fleet.
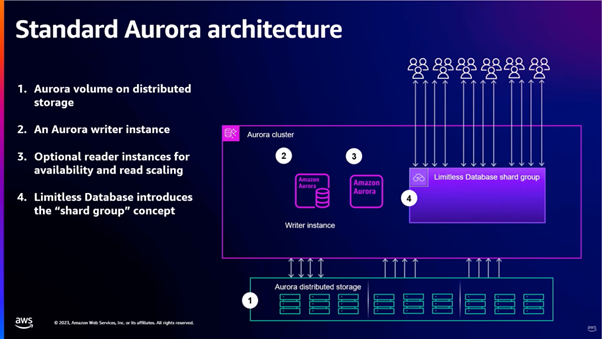
There are 2 main components to the shard group:
- Distributed Transaction Routers, and
- Data Access Shards
Both of which can scale both horizontally and vertically.
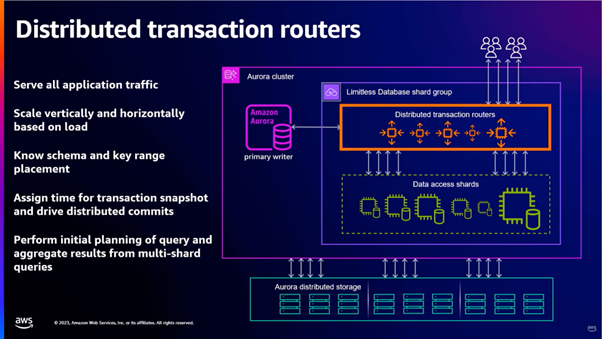
The routers serve all application traffic, where each router is itself a lightweight Aurora database, to perform initial planning of the queries and aggregate results of multi-shard queries. They are also responsible for ensuring isolation and consistency. These routers only store enough metadata to understand the schema and key range placements in the shards (i.e. in which shard each of the data lies). Specifically, this is done through hash-range partitioning.
In hash-range partitioning, each shard key is hashed to 64 bits and different ranges of this 64-bit space (each range is called a “table fragment”) are then assigned to each shard. The routers store references to these table fragments.
The data access shards then only store the table fragments (not actual data of sharded tables) and full copies of reference tables, where each of these shards acts as a Caspian database instance. Note that this table fragment strategy is only possible due to Amazon Aurora’s separation of the storage and compute layer (explained in [5]). These shards are also responsible for executing local transactional logic on the portion of data that they own.
Querying through the shard group then flows as such:

Scaling in Aurora Limitless
Recalling back to the previous section: each of the shards acts as a Caspian instance in itself. Similarly, as mentioned in The Sharding Problem section: a fleet of Caspian instances can handle seamless scaling up to the limits of a physical machine. This means that currently, our shard group can handle scaling up to this point as well – but what happens once this limit is reached? At this point, a shard may split into 2 new shards through a method called horizontal scale-out.
Before talking about the scaling process, it is worth mentioning table slicing. Each table fragment is further partitioned into sub-range slices (i.e. partitions of a partition). Though this is not directly visible to the users, this improves intra-shard parallelism and forms the basis of the scaling out process.
Horizontal scale-out (also called “shard split”) can occur due to sufficient change in utilization or storage size, determined by Caspian’s heat map. The table slices of relevant table fragments are then moved around, where slices of collocated tables will be moved together.
Note that the actual moving process heavily leverages Aurora storage-level cloning and replication – meaning that most of the work is handled by the underlying Aurora distributed storage system, rather than within the data access shard themselves. This avoids putting extra workload on any hot shards we are trying to split.

But how could Aurora clone and repartition the table slices so efficiently? This is made possible through Grover, Aurora’s internally optimized distributed database system that allows Aurora to disaggregate database components from storage. In a nutshell, Grover allows the database to be stored as logs – using writeahead logging to log each change without having to immediately sync to durable storage. This allows table slices to be moved around quickly, as writing logs require much less sequential IO. Additionally, this enables HA by replicating these logs across AZs without users having to manually set them up.
Consistency & Isolation in Aurora Limitless
Before discussing the consistency of Aurora Limitless, it is worth noting the importance of both consistency and isolation in such a distributed database. With a single-node database, ensuring consistency is trivial. For a database that does not support transactions, we do not need to consider isolation. As Aurora Limitless is a transactional distributed database system, both are required. If it is consistent without isolation, a lost update may occur; if it has isolation without consistency, a stale read may occur [6].
Firstly, regular Aurora can guarantee strong consistency (i.e. every successful read will receive the most recent write), as it is trivially a single node instance. While if read replicas are being used, any requests made through these replicas will only guarantee eventual consistency (i.e., the most recent write will eventually be reflected in future reads). This is because upon new updates on the primary DB instance, RDS copies them asynchronously to the replicas, with a non-instantaneous level of delay. If a read is requested to the replica before these updates are propagated, the results may not be up to date.
As the Aurora Limitless shard group presents itself as a single interface, it similarly guarantees strong consistency, with (currently) 2 options for isolation levels: READ COMMITTED (i.e. see the latest committed data before individual queries – each query in a transaction may see different data) and REPEATABLE READ (i.e. see the latest committed data before individual transactions – each query in a transaction will see the same data).
Normally, maintaining isolation whilst being efficient in a distributed system is extremely difficult, as each query fragment needs to be executed at different times, in a specific order, across different shards, and also in parallel (as we need parallelism). Aurora Limitless achieved this by utilizing a bounded wall clock.
Put simply, each query fragment has a timestamp attached to it that indicates to the data access shard when the query is meant to be executed, in the intended order. This “timestamp” is handled by the transaction routers and is directly integrated into DMBS itself (currently just PostgreSQL), which ensures a global read-after-write with a one-phase commit for local writes, and a two-phase commit for inter-shard writes.
Note that the “timestamp” logic only works sufficiently due to the facts that:
- All the distributed transaction routers are always in sync such that the DDLs are strongly consistent
- The internal clock of each data access shard is adequately synced
The second point here is crucial, as (according to [1]) the average clock in a server drifts by about one second per month – although this may not be much, this makes timestamp worthless as a sequence number. This problem is solved using Amazon Time Sync Service to keep the fleet in sync. With the new version announced back at Re:Invent, is now able to sync time within microseconds of UTC (on supported instances) using specialized hardware.
The Time Sync Problem
Without going into too much detail, it is worth looking further into this time sync problem, as syncing clocks is not as simple as one server telling the other what time it is: the time it takes to send a timestamp from one server to another varies and without knowing this propagation time (i.e. the time it takes to propagate timestamp from one server to another), the clocks can’t be synced with great precision.
Typically, time sync protocols such as NTP and PTP calculate the propagation time by sending round-trip messages. However, the problem here is variability: the protocol works over the same network, OS, and devices being used to handle the usual workload, which all introduces variability in the propagation time. In a small network, this can be mitigated if we choose to allocate a sufficiently large portion of the network for time sync, but on a regional or global scale, this can become an issue.
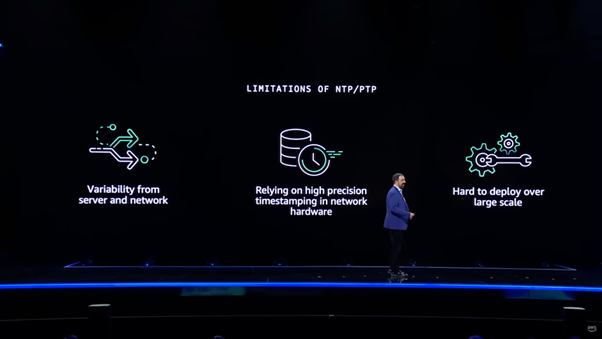
AWS solved the variability problem through a novel approach: having built-in custom hardware support for syncing the local clock, based on time pulse delivered from a custom time sync network, on their Nitro chips. The time pulse itself is delivered from a specialized time sync rack placed in each AZ that receives an extremely precise timing signal from a satellite-based atomic clock, which is distributed directly (via wires) into every instance. Every step of this time pulse distribution is done in hardware – i.e. no drivers, OS or any network buffers that would introduce variabilities.
Summary
Aurora Limitless was introduced to allow scaling of Aurora beyond the constraints of a single writer instance. To address this limitation, AWS employed sharding: partitioning data across multiple machines. This introduced several complexities surrounding querying, scaling, consistency and isolation. By building on previous breakthroughs such as Aurora’s Grover and Aurora Serverless Caspian, and improvement in other adjacent services such as Amazon Time Sync Service, AWS was able to overcome all these limitations, resulting in Aurora Limitless as we know it.